Tasks

The expert operator completes task with the robot. These tasks from left to right, from the first row are Pickup Dice Toy, Pickup Dinosaur Doll, Box Rotation, Scissor Pickup, Cup Stack. On the second row, two cup stacking, pouring cubes onto plate, cup into plate, open drawer and open drawer and pickup cup.
Method
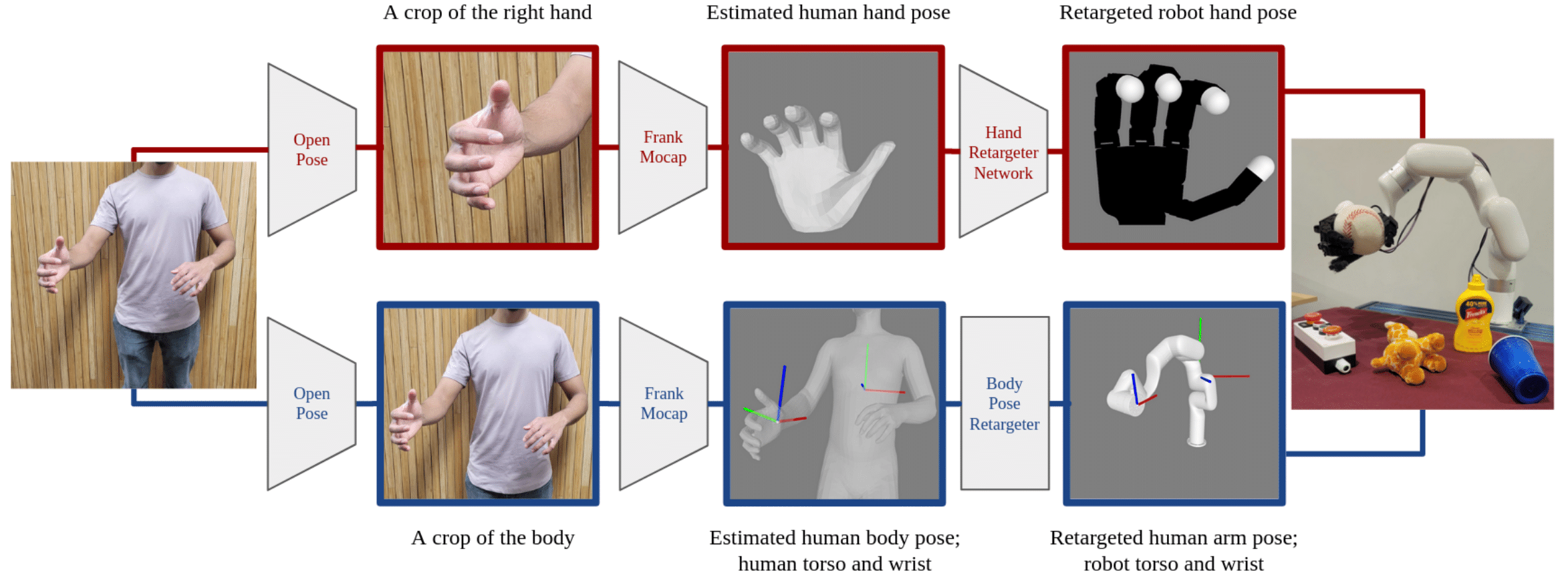
Our system: Consists of an xArm6 robot arm, a 16-DoF Allegro robot hand and a single RGB camera that captures a stream of images of the human operator. The camera can be placed anywhere as long as the operator is within the camera's field of view. Each captured image at 30hz is retargeted into a pair of robot commands (one for the Allegro hand and one for the xArm) which place the robot hand and arm in poses that match the hand-arm poses of the human operator. This capture-retarget-command loop allows the operator to guide the robot to complete tasks while watching the robot mimic them in real-time. The figure illustrates operators using the system to solve a pair of grasping tasks.
Remote Teleoperation
An operator completing a dice pickup task while watching the robot through a video conference.
Human Subject Study
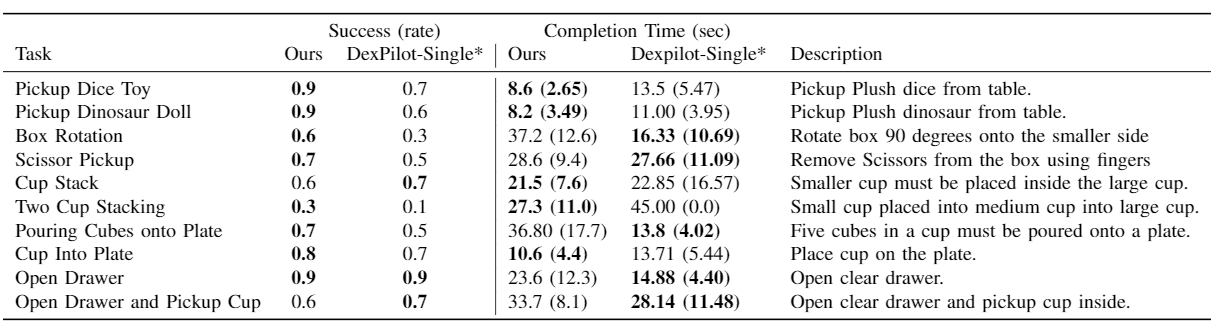
Success rate and completion time of a trained operator completing a variety of tasks using two methods. Our system outperforms the baseline in 7 out of 10 tasks and is either equal or similar in performance on the other three tasks. In practice, users found our system to be more fluid and easier to control. *Dexpilot-Single is reimplementation of Dexpilot with one camera instead of four and using a gradient descent solver as original code was not released.
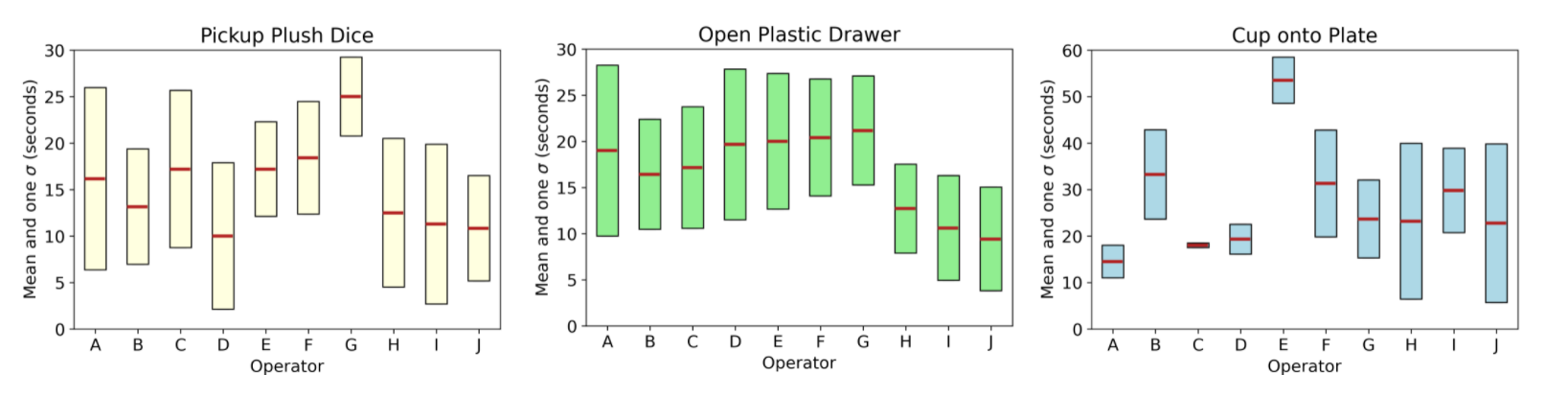
Ten rookie operators were asked to complete tasks: Picking up a plush dice, opening a plastic drawer, and placing a cup onto a plate. After seven tries at each task, the mean and standard deviation of their completion times were recorded per task.
Neural Network Retargeter
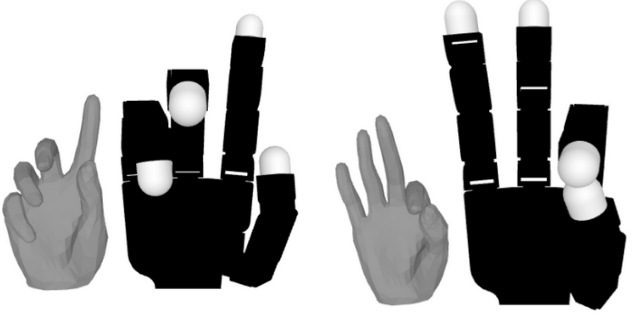
Human-to-robot Translations: The inputs and outputs of our hand retargeting network. Each of the pairs depicts a human hand pose, and the retargeted Allegro hand pose.
Self-Collision Avoidance via Adversarial Training

We compare a vanilla hand retargeting network versus ours with a self-collision loss. The red boxes highlight instances where the vanilla network outputs Allegro hand poses that result in self-collision. The green boxes depict the predictions of the network trained with self-collision loss. These robot hand poses maintain functional similarity to the human's hand pose, but avoid self-collision.
Experiment Videos from Untrained Operators
Collage of various inexperienced and untrained operators completing tasks with Telekinesis.
Featured Media

We are grateful to Ankur Handa for initial feedback and to Shikhar Bahl, Murtaza Dalal and Russell Mendonca for feedback on the paper. We would also like to thank Murtaza Dalal, Alex Li, Kathryn Chen, Ankit Ramchandani, Ananye Agarwal, Jianren Wang, Zipeng Fu, Aditya Kannan, Sam Triest for helping with experiments. KS is supported by NSF Graduate Research Fellowship under Grant No. DGE2140739. The work was supported in part by NSF IIS-2024594 and GoodAI Research Award.